L’objectif ici est de créer un graphe à partir d’un fichier CSV correspondant a une matrice d’adjacence.
Le fichier CSV
Voici un exemple de fichier CSV :
1;1;0;0;1;0
1;0;1;0;1;0
0;1;0;1;0;0
0;0;1;0;1;1
1;1;0;1;0;0
1;0;0;1;0;0Chaque indice de ligne et de colonne correspond a un noeud du graph.
Si l’intersection da la ligne i avec la colonne j vaut 1, cela signifie que le noeud i et le noeud j sont reliés.
Le processus
Pré-requis: APOC
Pour réaliser le script d’import, je vais utiliser certaines procédures de la librairie APOC.
Voici les étapes pour son installation :
-
Télécharger le JAR ici : https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/3.3.0.1/apoc-3.3.0.1-all.jar
-
Copier le JAR dans le répertoire
NEO4j_HOME/plugins -
Editer le fichier de configuration de Neo4j
NEO4J_HOME/conf/neo4j.conf -
Ajouter les propriétés suivantes :
# To be able to execute APOC procedures
dbms.security.procedures.unrestricted=apoc.*
# To allow APOC procedure to import files
apoc.import.file.enabled=true-
Redémarrer le serveur Neo4j
Le schema
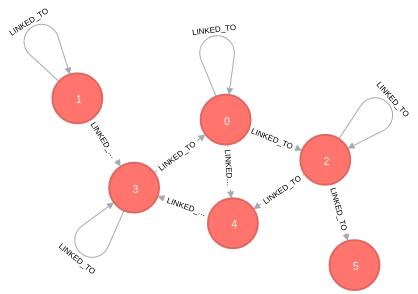
Le schéma de la base est ici tout simple :
-
des noeuds avec le label
Node, qui possèdent un attributidde typeentiercorrespondant a leur indice dans la matrice -
les noeuds seront reliés entre eux par une relation de type
LINKED_TO
Ainsi pour améliorer les performances de la base et assurer la cohérence des données, on va créer une contrainte d’unicité sur le champs id des noeuds Node :
CREATE CONSTRAINT ON (n:Node) ASSERT n.id IS UNIQUE;Le script d’import
Voici le script permettant d’importer le graphe :
CALL apoc.load.csv('file:///home/bsimard/Applications/neo4j/current/import/matrice.csv',{}) YIELD lineNo AS lineNumber, list AS line
MERGE (lineNode:Node { id:lineNumber})
WITH lineNode, line
UNWIND range(0,size(line)-1, 1) AS colNumber
MERGE (colNode:Node { id:colNumber})
WITH line, colNode, lineNode, colNumber
CALL apoc.do.when(
line[colNumber] = '1',
'MERGE (lineNode)-[:LINKED_TO]-(colNode)',
'',
{lineNode:lineNode, colNode:colNode}
) YIELD value
RETURN *A la ligne 1, permet de lire le fichier CSV correspondant a la matrice d’adjacence ligne par ligne.
A la ligne 3 on crée le noeud correspondant a la ligne en cours, si celui-ci n’existe pas grâce a l’instruction MERGE.
La ligne 6 permet d’itérer sur les colonnes de la ligne.
A la ligne 8 on crée le noeud correspondant a la colonne en cours, si celui-ci n’existe pas grâce a l’instruction MERGE.
De la ligne 11 a 16, on vérifie le contenu de la cellule (lineNumber, colNumber). Si celui-ci vaut 1, on crée la relation entre les deux noeuds si celle-ci n’existe pas déjà.
Et voilà, la matrice d’adjacence est chargé dans Neo4j !