L’objectif
Durant ce billet, nous allons utiliser Neo4j sur les données ouvertes de JCDecaux pour trouver les 5 stations de Vélo-partage les plus proches de ma position, ayant un vélo disponible.
Je vais vous montrer comment réaliser un modèle en graphe, charger les données depuis l’API JSON, faire quelques requêtes Cypher et finir sur une petite application web pour afficher le tout.
C’est parti !
Le modèle de JCDecaux
JCDecaux fournit une API pour les informations sur leur services de vélos. La documentation est disponible ici : https://developer.jcdecaux.com
INFO: vous devez créer un token pour utiliser leur API. Dans mes examples, vous devrez remplacer @JCD_TOKEN_API@ par le votre.
En lisant la document 'real-time', on peut en définir que JCD utilise le mod̀le suivant :
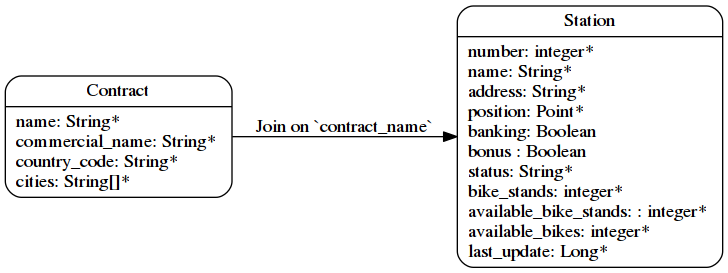
Il y a deux entités, liées ensemble : c’est le début d’un graphe ! Mais on peut faire mieux …
Si on regarde l’entité Contact, on voit :
-
une dépendance à un pays
-
une liste de ville
Donc explosons la !

Et si on regardait à présent le noeud Station ? Il est facile de voir qu’on peut le séparer en deux
-
les données statiques
-
les données éphémères
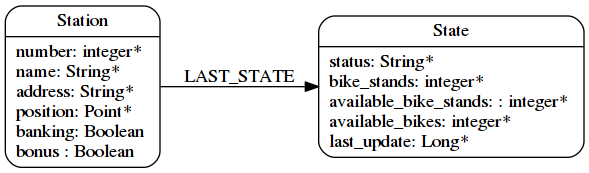
Mais que fait-on si on a envie de garder l’historique des données ?
Et bien il suffit de créer une chaine de noeuds State.
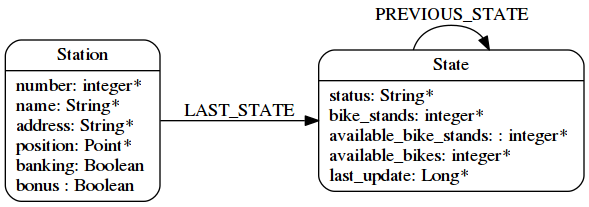
J’ai choisi cette modélisation car mon principal objectif est d’obtenir les derniéres données (ie. l’état courant de la station). Avec ce système je n’ai qu’à traverser une seule relation, et je garde l’historique.
Donc mon schéma final ressemble à cela :
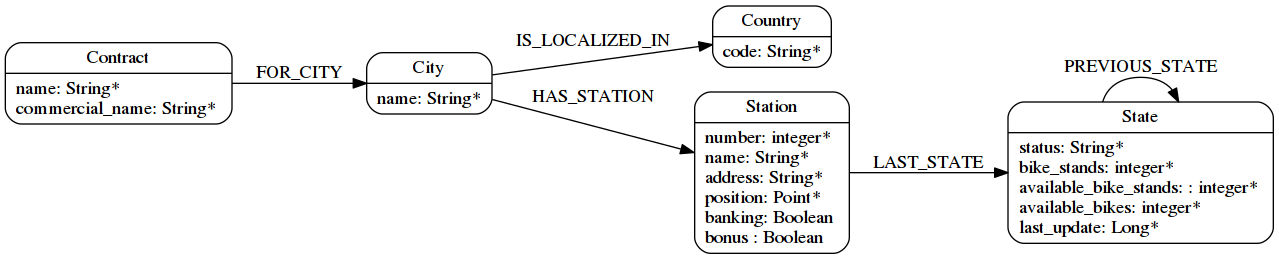
A présent que nous avons notre modèle, passons à l’étape d’import.
L’import
Pré-requis
Avant de commencer, il vous faut installer APOC. Il s’agit d’une collection de procédures stockées très utiles, dont je ne peux plus me passer.
Voici la procédure de son installation :
-
Télécharger la dernière version de la librairie à l’adresse suivante : https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/3.0.4.1/apoc-3.0.4.1-all.jar
$> cd NEO4J_HOME/plugins
$> wget https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download/3.0.4.1/apoc-3.0.4.1-all.jar-
Redémarrer le serveur Neo4j
$> bin/neo4j restartLes contraintes
Dans Neo4j nous pouvons créer des contraintes d’unicité, ce qui permet de s’assurer de la cohérence de nos données, mais aussi d’accélèrer la recherche d’un noeud via son identifiant.
Ceci va être utile pour la phase d’import pour s’assurer qu’on ne crée pas deux fois le même noeud.
// Contract name is unique
CREATE CONSTRAINT ON (n:Contract) ASSERT n.name IS UNIQUE;
// Country code is unique
CREATE CONSTRAINT ON (n:Country) ASSERT n.code IS UNIQUE;
// Station ID is a composition of the contract's name and the station id.
// Because the number field into the Station entity is only unique inside a contract
CREATE CONSTRAINT ON (n:Station) ASSERT n.id IS UNIQUE;
// State id is a composition of the station id plus the last_update timestamp
CREATE CONSTRAINT ON (n:State) ASSERT n.id IS UNIQUE;Il est a noter qu’ici je n’ai pas créé de contrainte sur les villes. C’est juste parce que deux pays peuvent avoir une ville avec le même nom. Mais si on le souhaite, on peut créer un index dessus, pour accélérer nos recherches de ville par leur nom.
CREATE INDEX ON :City(name);Import des contrats
La seconde étape consiste à importer la liste des contrats de JCD. Pour ce faire nous allons utiliser l’endpoint suivant : https://api.jcdecaux.com/vls/v1/contracts.
Et voici la requête :
WITH '@JCD_TOKEN_API@' AS key
CALL apoc.load.json('https://api.jcdecaux.com/vls/v1/contracts?apiKey=' + key) YIELD value as row
MERGE (contract:Contract { name: row.name, commercial_name:row.commercial_name })
MERGE (country:Country { code: row.country_code })
WITH row, contract, country
UNWIND row.cities AS cityName
MERGE (country)-[:HAS_CITY]->(city:City { name: cityName })
MERGE (contract)-[:FOR_CITY]->(city)Importer les stations et leur état
Maintenant que nous avons les contrats, nous allons pouvoir importer les stations avec leur état, grâce au endpoint suivant : https://api.jcdecaux.com/vls/v1/stations?contract=@contract_name@
`@contract_name@ ` doit simplement être remplacé par le nom commercial du contrat afin d’obtenir la liste des stations de celui-ci.
Voici la requête :
CALL apoc.periodic.iterate(
"MATCH (c:Contract) RETURN c",
"WITH '@JCD_TOKEN_API@' AS key , {c} AS contract
CALL apoc.load.json('https://api.jcdecaux.com/vls/v1/stations?contract=' + contract.name + '&apiKey=' + key) YIELD value as row
// we can find the same station number on two contracts, so the unique id is a compisition of the id and the contract
MERGE (contract)-[:HAS_STATION]->(station:Station {id: row.contract_name + '_' + row.number})
ON CREATE SET
station.number = row.number,
station.name = row.name,
station.address = row.address,
station.lat = row.position.lat,
station.lng = row.position.lng,
station.banking = row.banking,
station.bonus = row.bonus
// to have a unique id, I'm using a composition of the station id and the last_update timetsamp
MERGE (state:State {id: station.id + '_' + row.last_update})
ON CREATE SET
state.status = row.status,
state.available_bikes = row.available_bikes,
state.bike_stands = row.bike_stands,
state.available_bike_stands = row.available_bike_stands
WITH station, state
MERGE (station)-[:LAST_STATE]->(state)
// Here we remove the previous `LAST_STATE` rel if it exists, and we create the chain
WITH station, state
MATCH (old:State)<-[r:LAST_STATE]-(station)-[:LAST_STATE]->(state)
WHERE NOT id(old) =id(state)
WITH old, r, state
CREATE (state)-[:PREVIOUS]->(old)
DELETE r",
{batchSize:1,parallel:true}) YIELD batches, total, errorMessagesLa première instruction est apoc.periodic.iterate. Il s’agit d’une procédure stockée qui prend 3 paramêtres :
-
Une requête cypher qui permet d’obtenir une première collection de résultat
-
Une autre requête qui va s’appliquer sur chacun des résultats de la première
-
De la configuration (ici
{batchSize:1,parallel:true})
Basiquement, cela ressemble à un WITH (ie. itérer sur les résultats d’une requête), mais avec des possiblités de batch (basé sur le nombre d’itération de la première requêete), et de parallélisation.
Donc ici, je crée juste un job par Contrat pour créer les stations.
Vous pouvez rejouer ce script toutes les 5 minutes afin de mettre à jour l’état des stations, vu que j’utilise l’instruction MERGE, qui permet de selectionner une noeud et de le créer s’il n’exsite pas.
Un cron job est suffisant, ou vous pouvez aussi utiliser la procedure apoc.periodic.repeat (Les jobs ne sont pas persistés, donc a chaque redémarrage de Neo4j il faudra rejouer recréer le job).
Si vous avez bien suivi les étapes, vous devriez avoir un graph ressemblant à cela :
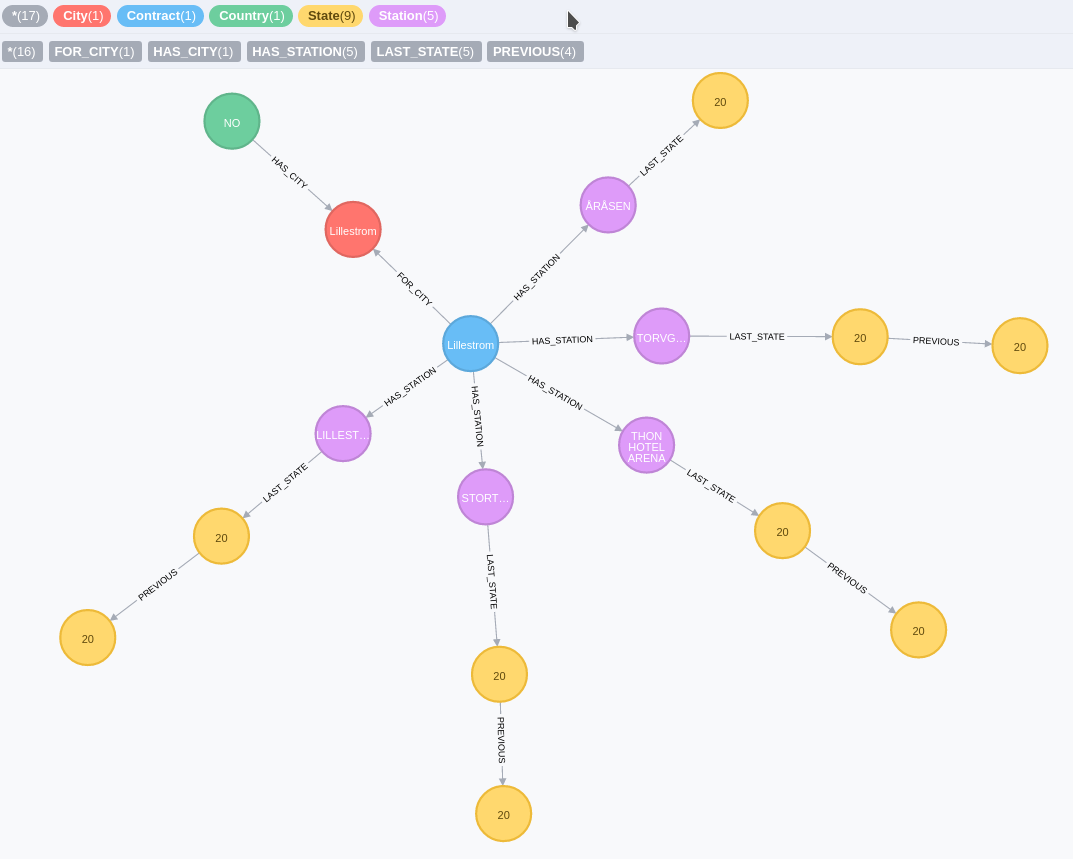
Amusons-nous maintenant !
Maintenant que nous avons une base opérationnelle avec les données, pourquoi ne pas lui demander la liste des stations les plus proches avec un vélo disponible :
WITH point({latitude: 56.7, longitude: 12.6}) as my_position
MATCH (station:Station)-[:LAST_STATE]->(state:State)
WHERE state.status = "OPEN" AND state.available_bikes > 0
RETURN station, distance(point({latitude: station.lat, longitude: station.lng}), poi) AS distance
ORDER BY distance
LIMIT 5J’utilise deux nouvelles fonctions de Neo4j 3.1 :
-
point( { latitude: XXX, longitude: XXX} ) : permets de créer un point geospatial avec la projection WGS-83.
-
distance( point, point) : retourne la distance géodésique entre deux points.
C’est bien, mais nous pouvons avoir de meilleur performances en créant ces deux indexes (je vous laisse faire les EXPLAIN des requête avant et après) :
CREATE INDEX ON :State(available_bikes);
CREATE INDEX ON :State(status);Ok, et si je veux afficher ces données sur une carte avec du geojson ? Cypher sachant construire du json, il suffit de lui dire comment :
WITH point({latitude: 56.7, longitude: 12.6}) as my_position
MATCH (station:Station)-[:LAST_STATE]->(state:State)
WHERE state.status = "OPEN" AND state.available_bikes > 0
WITH station, state, distance(point({latitude: station.lat, longitude: station.lng}), my_position) AS distance
ORDER BY distance
LIMIT 5
WITH collect( {
type: 'Feature',
geometry: {
type: 'Point',
coordinates: [station.lng, station.lat]
},
properties : {
name : station.name,
distance: round(distance),
address : station.address,
free_bike: state.available_bikes,
free_slot: state.available_bike_stands
}
}) AS features
RETURN { type: 'FeatureCollection', features: features } AS geojsonPour voir le résultat (et vérifier la validité du geoJson), vous pouvez copier/coller le résultat de la requête dans http://geojson.io/
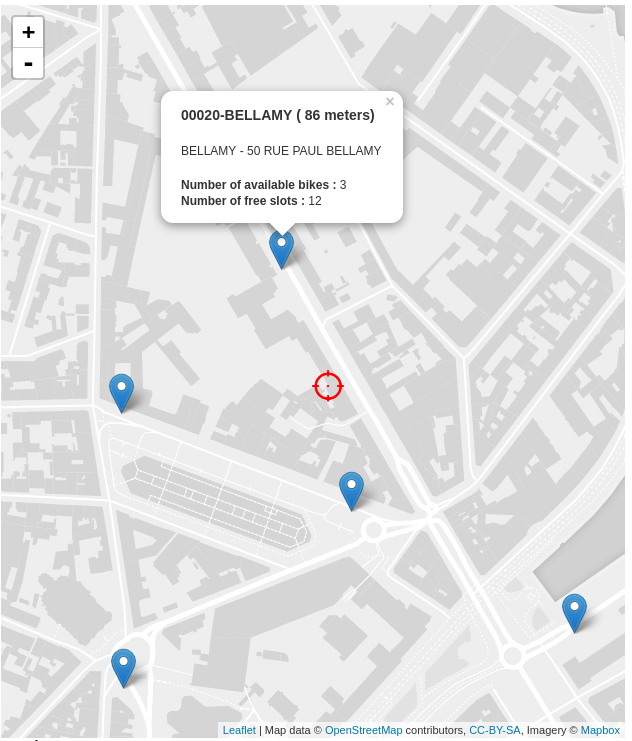
Ou, si vous avez suivi les differentes étapes, vous pouvez utiliser cette petite page web qui affiche les résultats grace a Leaflet : Comme ici.
Voici le rendu finale :