

Description
This project aims to create a referencial of all the lego sets, with theirs pieces. So after, if you have a partial set, you will know wich piece to search to have a complete one.
All the information comes from the website rebrickable.com, where you can download all the lego information under a CC-BY-SA : http://rebrickable.com/downloads
Meta-graph
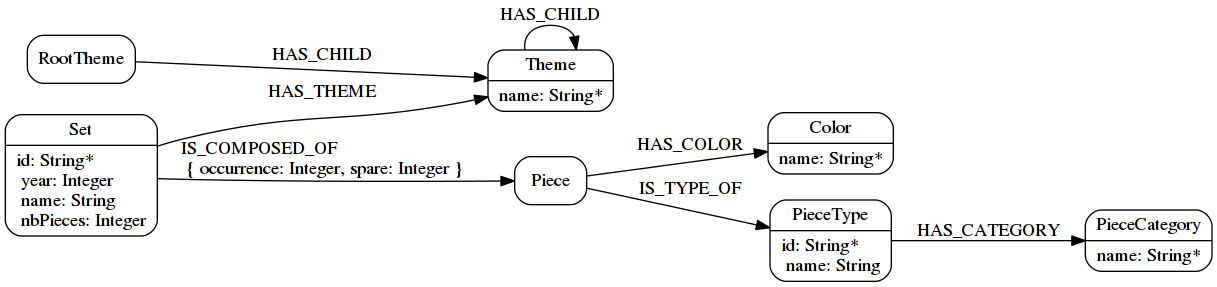
Import database
The dataset is composed of 4 files :
-
colors.csv :
id,descr -
pieces.csv :
piece_id,descr,category -
sets.csv :
set_id,year,pieces,t1,t2,t3,descr -
set_pieces.csv :
set_id,piece_id,num,color,type(type : 1=normal, 2=spare)
Just put those files into NEO4J_HOME/import folder.
Schema definition
Constraints
Execute those commands with NEO4J_HOME/bin/neo4j-shell tools :
CREATE CONSTRAINT ON (n:PieceCategory) ASSERT n.name IS UNIQUE;
CREATE CONSTRAINT ON (n:Color) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:Set) ASSERT n.id IS UNIQUE;
CREATE CONSTRAINT ON (n:PieceType) ASSERT n.id IS UNIQUE;Indexes
Execute those command with NEO4J_HOME/bin/neo4j-shell tools :
CREATE INDEX ON :Set(name);
CREATE INDEX ON :PieceType(name);
CREATE INDEX ON :Color(name);
CREATE INDEX ON :Theme(name);The import scripts
You can execute those scripts one at a time into the browser (http://localhost:7474/browser) or via the neo4j-shell tool.
Colors
LOAD CSV WITH HEADERS FROM 'file:///colors.csv' AS row
CREATE (c:Color { id:row.id, name:row.descr });Pieces Type
LOAD CSV WITH HEADERS FROM 'file:///pieces.csv' AS row
CREATE (pt:PieceType { id:row.piece_id, name:row.descr })
MERGE (c:PieceCategory { name:row.category })
CREATE UNIQUE (pt)-[:HAS_CATEGORY]->(c);Sets
Firstly, we create the RootTheme node :
CREATE (:RootTheme);Then we import the sets.csv files :
LOAD CSV WITH HEADERS FROM 'file:///sets.csv' AS row
MATCH (rt:RootTheme)
CREATE (s:Set { id:row.set_id, name:row.descr, year:toInt(row.year), nbPieces:0})
MERGE (rt)-[:HAS_CHILD]->(t1:Theme { name: coalesce(row.t1, '@@')})
MERGE (t1)-[:HAS_CHILD]->(t2:Theme { name: coalesce(row.t2, '@@')})
MERGE (t2)-[:HAS_CHILD]->(t3:Theme { name: coalesce(row.t3, '@@')})
CREATE (s)-[:HAS_THEME]->(t3);Note that sometimes t1, t2 & t3 can be null, so in the above script we make some trick to import them with some dummy value.
But this mean that after the execution, we have some clean-up todo :
Clean-up level 3
MATCH (rt:RootTheme)-[:HAS_CHILD]->(t1:Theme)-[:HAS_CHILD]->(t2:Theme)-[:HAS_CHILD]->(t3:Theme)
WHERE t3.name CONTAINS '@@'
WITH t2, t3
MATCH (t3)<-[r:HAS_THEME]-(s:Set)
DELETE r
CREATE (t2)<-[:HAS_THEME]-(s);Clean-up level 2
MATCH (rt:RootTheme)-[:HAS_CHILD]->(t1:Theme)-[:HAS_CHILD]->(t2:Theme)
WHERE t2.name CONTAINS '@@'
WITH t1, t2
MATCH (t2)<-[r:HAS_THEME]-(s:Set)
DELETE r
CREATE (t1)<-[:HAS_THEME]-(s);Delete orphelan theme node
MATCH (t:Theme)
WHERE
size((t)-[:HAS_CHILD]->()) = 0 AND
size((t)<-[:HAS_THEME]-(:Set)) = 0
WITH t
DETACH DELETE t;Sets pieces
To have better performances, we split the script into three parts :
The creation of the Piece node (unique per type and color):
LOAD CSV WITH HEADERS FROM 'file:///set_pieces.csv' AS row
MATCH (pt:PieceType {id:row.piece_id})
MATCH (c:Color {id:row.color})
WITH pt, collect(DISTINCT c) AS colors
WITH pt, colors
UNWIND colors AS color
CREATE (p:Piece)
CREATE (p)-[:IS_TYPE_OF]->(pt)
CREATE (p)-[:HAS_COLOR]->(color);And the link between the Set and its Piece :
USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM 'file:///set_pieces.csv' AS row
WITH row WHERE row.type = '1'
MATCH (s:Set {id:row.set_id})
MATCH (:Color {id:row.color})<-[:HAS_COLOR]-(p:Piece)-[:IS_TYPE_OF]->(:PieceType {id:row.piece_id})
CREATE (s)-[r:IS_COMPOSED_OF {occurrence:toInt(row.num)}]->(p)
SET s.nbPieces = s.nbPieces + toInt(row.num);Merge the link between the Set and Piece for spare pieces :
USING PERIODIC COMMIT 10000
LOAD CSV WITH HEADERS FROM 'file:///set_pieces.csv' AS row
WITH row WHERE row.type = '2'
MATCH (:Set {id:row.set_id})-[r:IS_COMPOSED_OF]->(p:Piece),
(:Color {id:row.color})<-[:HAS_COLOR]-(p)-[:IS_TYPE_OF]->(:PieceType {id:row.piece_id})
SET r.spare = toInt(row.num);Some queries
Piece queries
Number of piece type
MATCH (pt:PieceType)
RETURN count(pt) AS nbPieceType;Number of piece
MATCH (p:Piece)
RETURN count(p) AS nbPiece;Number of pieces type per category
MATCH (p:PieceType)-[:HAS_CATEGORY]->(c:PieceCategory)
RETURN c.name AS category, count(p) AS count
ORDER BY category ASC;Get piece type info
MATCH (c:Color)<-[:HAS_COLOR]-(:Piece)-[:IS_TYPE_OF]->(pt:PieceType {name:"Technic Beam 1 x 11 Thick" })-[:HAS_CATEGORY]->(c:PieceCategory)
RETURN pt.name AS name, c.name AS category, COLLECT(c.name) AS colors;Fabrications years of a piece
MATCH (s:Set)-[:IS_COMPOSED_OF]->(:Piece)-[:IS_TYPE_OF]->(:PieceType {name:"Technic Beam 1 x 11 Thick" })
RETURN DISTINCT s.year AS year ORDER BY year ASC;Colors available for a piece type
MATCH (p:Piece)-[:IS_TYPE_OF]->(pt:PieceType {name:"Technic Beam 1 x 11 Thick" }),
(p)-[:HAS_COLOR]->(c:Color)
RETURN DISTINCT c.name AS color
ORDER BY color ASC;List of set where a piece type appears by year
MATCH (s:Set)-[:IS_COMPOSED_OF]->(:Piece)-[:IS_TYPE_OF]->(:PieceType {name:"Technic Beam 1 x 11 Thick" })
RETURN DISTINCT s.name AS set, s.year AS year
ORDER BY year DESC, set ASC;List of set where piece appears with its number of occurrence
This query can be usefull if you have a missing piece and you want to search a partial set where it’s frequent to find it.
MATCH (s:Set)-[r:IS_COMPOSED_OF]->(p:Piece),
(p)-[:IS_TYPE_OF]->(:PieceType {name:"Technic Beam 1 x 11 Thick" }),
(p)-[:HAS_COLOR]->(:Color { name:"Black"})
RETURN s AS set, r.occurrence AS occurrence
ORDER BY occurrence DESC, set.name ASC;Set queries
Number of sets
MATCH (s:Set)
RETURN count(*) AS nbSet;Number of set per top-theme
MATCH (:RootTheme)-[:HAS_CHILD]->(t),
(t)-[:HAS_CHILD*]->(st)-[:HAS_THEME]-(s:Set)
RETURN t.name AS name, count(s)+ size((t)<-[:HAS_THEME]-(:Set)) AS count
ORDER BY name ASC;Number of set per year
MATCH (s:Set)
RETURN s.year AS year, count(s)
ORDER BY year ASC;Is there some sub-set of a set ?
Can I do an other (sub)set with a set ?
MATCH (s1:Set)-[r1:IS_COMPOSED_OF]->(p:Piece)<-[r2:IS_COMPOSED_OF]-(s2:Set)
WHERE s1.name = "The Kwik-E-Mart" AND
r2.occurrence <= (r1.occurrence + coalesce(r1.spare, 0))
WITH s1, s2, collect(id(p)) AS pieces
WHERE size(pieces) = size((s2)-[:IS_COMPOSED_OF]->(:Piece))
RETURN s2.name;Give me some pieces and I will construct the world
Initialize piece set for a person
Here we will create a user node, and attach to it the list of its pieces.
Firstly we will create a new constraint based on user email address :
CREATE CONSTRAINT ON (n:Person) ASSERT n.email IS UNIQUE;Then we create the user :
CREATE (me:Person { name:'Simard', firstname:'Benoit', email:'benoit@lego.com'});For the example, let’s consider that Benoit has all the piece to make the Taj Mahal
MATCH (me:Person {email:'benoit@lego.com'}),
(s:Set)-[r:IS_COMPOSED_OF]->(p:Piece)
WHERE s.name = 'Taj Mahal'
WITH me, r.occurrence AS nb, p
CREATE (me)-[:HAS_PIECE {occurrence:nb}]->(p);Give me all sets that can I do
With a given number of piece (type and number), what set can I do ?
// look at piece in common where user have enought number of pieces
MATCH (me:Person {email:'benoit@lego.com'})-[r:HAS_PIECE]->(p:Piece)<-[r2:IS_COMPOSED_OF]-(s:Set)
WHERE r2.occurrence <= r.occurrence
WITH s, count(p) AS nbPiecesType
// we look if the set is complete
WHERE nbPiecesType = size((s)-[:IS_COMPOSED_OF]->(:Piece))
RETURN s;Give me all sets that can pretty much do
With a given number of piece (type and number), what set can I pretty much do (missing at max 10% of pieces type) ?
MATCH (me:Person {email:'benoit@lego.com'}),
(s:Set)-[r:IS_COMPOSED_OF]->(p:Piece)
OPTIONAL MATCH (me)-[r2:HAS_PIECE]->(p)
WITH s,
p,
CASE
WHEN (r2.occurrence - r.occurrence) IS null THEN r.occurrence
WHEN (r2.occurrence - r.occurrence) < 0 THEN (r.occurrence - r2.occurrence)
ELSE 0
END AS missing
WITH s, sum(missing) AS nbMissingPieces
WHERE nbMissingPieces > 0 AND
(nbMissingPieces/toFloat(s.nbPieces) < 0.1
RETURN s, nbMissingPieces
ORDER BY nbMissingPieces ASC;