
In this article I will show you how to import all the components of a Linux computer (package network connection, user, group, …), into a graph with the help of Neo4j.
In an next article, we will play with this dataset and see what we value we can get.
The model
This is the model I want to produce :
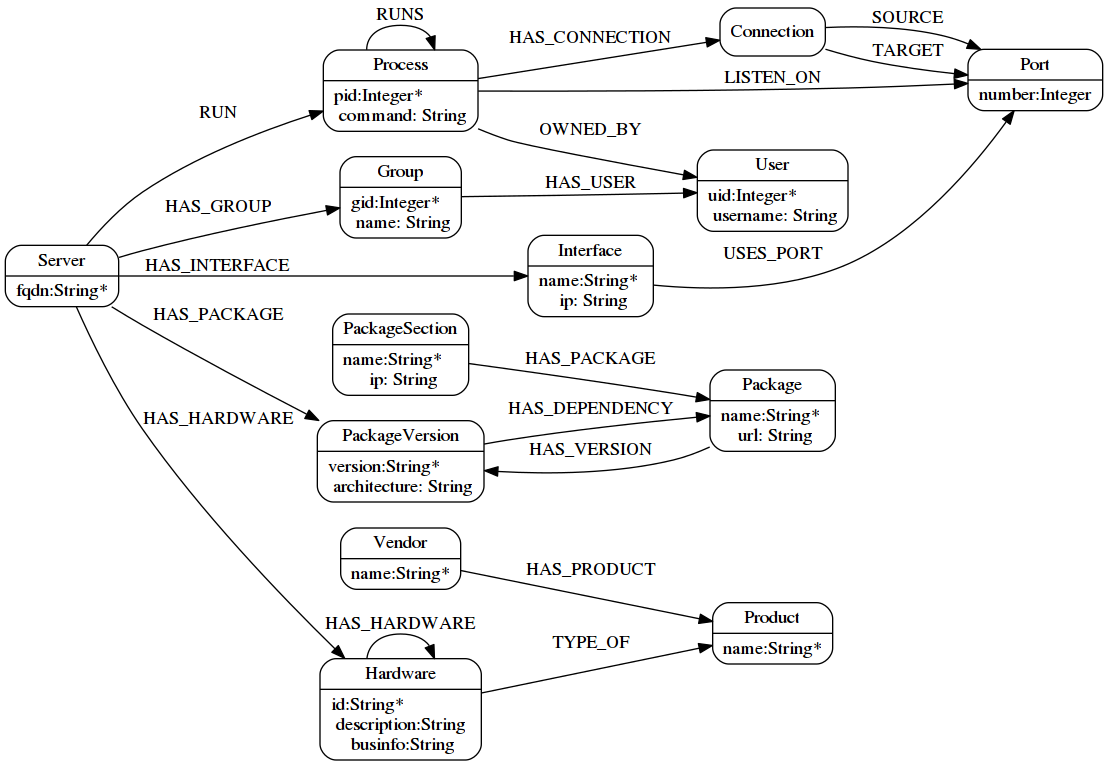
Basicaly, I have a server that is composed of a list of:
-
installed packages with their dependencies
-
network interfaces with their connections
-
hardware (as tree)
-
groups and users
-
process (as a tree)
From that model, we can create the indexes/constraints for the database :
CREATE CONSTRAINT ON (n:Server) ASSERT (n.fqdn) IS NODE KEY;
CREATE CONSTRAINT ON (n:Group) ASSERT (n.gid, n.fqdn) IS NODE KEY;
CREATE CONSTRAINT ON (n:User) ASSERT (n.uid, n.fqdn) IS NODE KEY;
CREATE CONSTRAINT ON (n:Process) ASSERT (n.pid, n.fqdn) IS NODE KEY;
CREATE CONSTRAINT ON (n:PackageSection) ASSERT (n.name) IS NODE KEY;
CREATE CONSTRAINT ON (n:Package) ASSERT (n.name) IS NODE KEY;
CREATE CONSTRAINT ON (n:PackageVersion) ASSERT (n.version, n.architecture,n.name ) IS NODE KEY;
CREATE CONSTRAINT ON (n:Hardware) ASSERT (n.id, n.fqdn ) IS NODE KEY;
CREATE CONSTRAINT ON (n:Vendor) ASSERT (n.name ) IS NODE KEY;
CREATE CONSTRAINT ON (n:Product) ASSERT (n.name, n.vendor ) IS NODE KEY;Import items
Computer name
The first thing to retrieve is the FQDN of the computer.
For this I will use the command : hostname --fqdn.
$> hostname --fqdn
pythagoreThis will help us to create the node Server :
MERGE (:Server {fqdn:$fqdn});Hardware
To retrieve the entire composition of the server,
I will use the command lshw that list all the hardware in a tree format.
Moreover, the command can generate a JSON file if we pass the argument -json:
FILE="$NEO4J_HOME/import/$1/hardware.json"
sudo lshw -json > $FILE{
"id" : "pythagore",
"class" : "system",
"claimed" : true,
"description" : "Computer",
"width" : 64,
"capabilities" : {
"vsyscall32" : "processus 32 bits"
},
"children" : [
{
"id" : "core",
"class" : "bus",
"claimed" : true,
"description" : "Motherboard",
"physid" : "0",
"children" : [
{
"id" : "memory",
"class" : "memory",
"claimed" : true,
"description" : "Mémoire système",
"physid" : "0",
"units" : "bytes",
"size" : 16695070720
}
...
]
}
]
}The import process of this file will be a little complexe, because it’s a JSON tree with an undeterminated depth. So I need to create a recursive query to create its structure in neo4j.
For this I will use massively APOC for that !
For each item of the JSON, I want to create this : (Vendor)-→(Product)←-(ProductInstance)←-(ParentHardwareInstance)
If I translate that in Cypher in a custom procedure, it gives that :
CALL apoc.custom.asProcedure(
'hardware',
"
MATCH (p) WHERE id(p)=$parent
MERGE (vendor:Vendor { name:coalesce($item.vendor, 'unknown')})
MERGE (product:Product { name:coalesce($item.product, 'unknown'), vendor:coalesce($item.vendor, 'unknown')})
ON CREATE SET product.description = $item.description
MERGE (vendor)-[:HAS_PRODUCT]->(product)
MERGE (hardware:Hardware {id:$item.id + '-' + coalesce($item.physid, '') + '-' + coalesce($item.handle, '') , fqdn:$fqdn})
SET hardware +=apoc.map.removeKeys($item,['id', 'children', 'capabilities', 'configuration', 'vendor', 'product'])
MERGE (p)-[:HAS_HARDWARE]->(hardware)
MERGE (hardware)-[:TYPE_OF]->(product)
WITH hardware
UNWIND coalesce($item.children, []) AS newItem
CALL custom.hardware($fqdn, id(hardware), newItem) YIELD row
RETURN row
",
"write",
[["row","MAP"]],
[
['fqdn','STRING'],
['parent','LONG'],
['item','MAP']
]
);As you see at the line 18, I recall the procedure itself if there are some children. Pretty cool no ?
|
Note
|
The documentation for the cypher custom procedure feature is available here : https://neo4j-contrib.github.io/neo4j-apoc-procedures/#cypher-based-procedures-functions |
Then I just have to call the procedure with the data like that :
CALL apoc.load.json("file:///" + $fqdn + "/hardware.json") YIELD value WITH value
MATCH (s:Server {fqdn:$fqdn})
CALL custom.hardware($fqdn, id(s), value) YIELD row
RETURN count(*);And to finish, I put the class attribut as a Label :
MATCH (n:Hardware)
CALL apoc.create.addLabels( id(n), [ n.class ] ) YIELD node
REMOVE node.class
RETURN count(*)If you want to see the result in the browser, this is the query for just displaying the tree structure of hardwares :
MATCH p=(n:Server {fqdn:'pythagore.logisima'})-[:HAS_HARDWARE]->(:Hardware)-[:HAS_HARDWARE*]->(h:Hardware)
WHERE NOT (h)-[:HAS_HARDWARE]->()
RETURN *
User & Group
Users
Users are stored in the file /etc/users, where each line represents a user.
For example : bsimard:x:1000:1000:Benoit Simard,,,:/home/bsimard:/bin/bash
-
Username: The login of the user,
bsimard -
Password: Generally password is set to
x. It indicates that password are stored in the file/etc/shadow. -
User ID (UID): The ID of the user.
-
Group ID (GID): The ID of the main group of the user
-
User ID Info: Some information about the user seperated by a
,, like the fullname, phone, email -
Home directory: The home directory of the user
/home/bsimard -
Command/shell: The command for the shell, in my case
/bin/bash
This is the Cypher script to import this file in Neo4j :
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/users.csv" AS row FIELDTERMINATOR ':'
MERGE (g:Group { gid:toInteger(row.gid), fqdn:$fqdn})
MERGE(u:User {uid: toInteger(row.uid), fqdn:$fqdn})
SET u.username = row.username,
u.fullname = split(row.info, ',')[0],
u.home_directory = row.home,
u.shell = row.shell
MERGE (g)-[:HAS_USER]->(u);Groups
Groups are stored in the file /etc/groups, where each line represents a group.
For example : adm:x:4:syslog,bsimard
-
Group name: Name of the group, in our example it’s
adm -
Password: Generally password is not used, hence it is empty/blan, ie.
x -
Group ID (GID): Each group must be assigned a group ID, , in our example it’s
4 -
Group List: It is a list of user names of users who are members of the group, separated by a
,. In our examplesyslogandbsimard
This is the Cypher script to import this file in Neo4j :
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/groups.csv" AS row FIELDTERMINATOR ':'
MATCH (s:Server {fqdn:$fqdn})
MERGE (g:Group { gid:toInteger(row.gid), fqdn:$fqdn })
MERGE (s)-[:HAS_GROUP]->(g)
SET g.name = row.name
WITH row, g
UNWIND split(row.users, ",") AS username
MATCH (u:User { username:username, fqdn:$fqdn})
MERGE (g)-[:HAS_USER]->(u);The result

Process list
To retrieve the list of all the running process, with their dependencies, I will use the ps command with those arguments :
-
e: Select all processes
-
o: To specify the format with
-
pid: The ID of the process
-
ppid: The ID of the parent process
-
comm: The command that has launched the process
-
ruser: The username of the user that owns the process
-
$> ps -eo pid,ppid,comm,ruser
PID,PPID,%CPU,SIZE,COMMAND,RUSER
1,0,0.0,18964,systemd,root
2,0,0.0,0,kthreadd,root
4,2,0.0,0,kworker/0:0H,root
6,2,0.0,0,mm_percpu_wq,rootWith the help of awk, we can generate a CSV file :
FILE="$NEO4J_HOME/import/$1/processes.csv"
ps -eo pid,ppid,comm,ruser | awk '{print $1","$2","$3","$4}' > $FILEAnd this is the cypher script to import it :
MATCH (s:Server {fqdn:$fqdn})
MERGE (p:Process {pid:0, command:'init', fqdn:$fqdn})
MERGE (s)-[:HAS_PROCESS]->(p);
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/processes.csv" AS row
WITH row ORDER BY row.PPID, row.PID ASC
MATCH (u:User {username:row.RUSER, fqdn:$fqdn})
MERGE (pp:Process {pid:toInteger(row.PPID), fqdn:$fqdn})
MERGE (p:Process {pid:toInteger(row.PID), fqdn:$fqdn})
SET p.command = split(row.COMMAND, '/')[0]
MERGE (pp)-[:HAS_PROCESS]->(p)
MERGE (p)-[:OWNED_BY]->(u);When the import is finished, you should have something similar to this by excuting the following query :
MATCH path=(n:Server {fqdn:'pythagore.logisima'})-[:HAS_PROCESS]->(:Process)-[:HAS_PROCESS*]->(p:Process)
WHERE NOT (p)-[:HAS_PROCESS]->()
RETURN *
We can also search all the processes of a user :
MATCH (n:Server {fqdn:'pythagore.logisima'})-[:HAS_GROUP|:HAS_USER*2..2]->(u:User {name:'bsimard'})
WITH u
MATCH (u)<-[:OWNED_BY]-(p)
RETURN *
List of installed packages
Because I have a debian system, I will use the dpkg command, and produce a CSV from its output :
FILE="$NEO4J_HOME/import/$1/packages.csv"
dpkg-query -Wf '${Section}\t${Package}\t${Version}\t${Architecture}\t${Homepage}\t${Depends}\n' >> $FILEI can import it with the following cypher script :
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/packages.csv" AS row FIELDTERMINATOR '\t'
MATCH (s:Server {fqdn:$fqdn})
MERGE (section:PackageSection {name:coalesce(row.section, 'None') })
MERGE (package:Package {name:row.package})
SET package.url = row.homepage
MERGE (section)-[:HAS_PACKAGE]->(package)
MERGE (pv:PackageVersion { version:row.version, architecture:row.architecture, name:row.package})
MERGE (package)-[:HAS_VERSION]->(pv)
MERGE (s)-[:HAS_PACKAGE]->(pv)
FOREACH( dep IN split(row.dependencies, ',') |
MERGE (depNode:Package {name:split(dep, '(')[0] })
MERGE (pv)-[r:HAS_DEPENDENCY]->(depNode)
SET r.constraint = replace(split(dep, '(' )[1], ')','')
);If you want to see the result, you can run the following query :
MATCH (n:Server {fqdn:'pythagore.logisima'})-[:HAS_PACKAGE]->(:Package)-[:HAS_PACKAGE*]->(p:Package)
WHERE NOT (p)-[:HAS_PACKAGE]->()
RETURN *
Network
Network interfaces
To get the list of the network interface, I will use the ip command with the following arguments :
-
r: See the routing table
-
n: Display the IP adresses
-
w: Don’t truncate IP addresses
$>ip -o addr show
1: lo inet 127.0.0.1/8 scope host lo\ valid_lft forever preferred_lft forever
1: lo inet6 ::1/128 scope host \ valid_lft forever preferred_lft forever
2: wlp58s0 inet 10.0.1.11/24 brd 10.0.1.255 scope global dynamic wlp58s0\ valid_lft 2720sec preferred_lft 2720sec
2: wlp58s0 inet6 fe80::cc06:f22c:2e3b:6aaf/64 scope link \ valid_lft forever preferred_lft forever
3: br-8a43a73a9b0d inet 172.24.0.1/16 brd 172.24.255.255 scope global br-8a43a73a9b0d\ valid_lft forever preferred_lft forever
4: br-f8fefbd33c18 inet 172.18.0.1/16 brd 172.18.255.255 scope global br-f8fefbd33c18\ valid_lft forever preferred_lft forever
5: br-0ba6b709cb23 inet 172.21.0.1/16 brd 172.21.255.255 scope global br-0ba6b709cb23\ valid_lft forever preferred_lft forever
6: docker0 inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0\ valid_lft forever preferred_lft forever
7: br-667de2307c35 inet 172.22.0.1/16 brd 172.22.255.255 scope global br-667de2307c35\ valid_lft forever preferred_lft forever
8: br-72683ea3a3d0 inet 172.19.0.1/16 brd 172.19.255.255 scope global br-72683ea3a3d0\ valid_lft forever preferred_lft foreverFor my need, I need the IP addresses (v4 & v6) of the Interface and its name. So by using awk, we can produce a CSV file :
FILE="$NEO4J_HOME/import/$1/network_interfaces.csv"
ip -o addr show | awk '{print $2","$3","$4}' >> $FILENow I can load it in Neo4j :
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/network_interfaces.csv" AS row
WITH row,
CASE WHEN row.type = 'inet' THEN split(row.ip, '/')[0] ELSE NULL END AS ipv4,
CASE WHEN row.type = 'inet6' THEN split(row.ip, '/')[0] ELSE NULL END AS ipv6
MATCH (s:Server {fqdn:$fqdn})
MERGE (i:Interface { name: row.name, fqdn:$fqdn })
SET i.ip = coalesce(ipv4, i.ip),
i.ipv6 = coalesce(ipv6, i.ipv6)
MERGE (s)-[:HAS_INTERFACE]->(i);It gives me the following graph :

Network connections
To see all the connections on our computer, I will use the netstat command, with the following arguments :
-
a: Display every socket
-
u: Filter on UDP sockets
-
t: Filter on TCP sockets
-
p: Display the process ID that use the socket
-
n: Display the IP adresses
-
w: Don’t truncate IP addresses
|
Note
|
you need to run this command as a root to see all the connections |
$> netstat -alpuetn
Connexions Internet actives (serveurs et établies)
Proto Recv-Q Send-Q Adresse locale Adresse distante Etat User Inode PID/Program name
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN 124 28742 1317/mysqld
tcp 0 0 127.0.1.1:53 0.0.0.0:* LISTEN 0 35483 3192/dnsmasq
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 0 4024761 5070/cupsd
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 125 28000 1434/postgres
tcp 0 0 127.0.0.1:38630 127.0.0.1:7687 ESTABLISHED 1000 4856935 14182/firefox
tcp 0 0 10.0.1.11:39694 198.252.206.25:443 ESTABLISHED 1000 5159133 14182/firefox
tcp 0 0 127.0.0.1:39044 127.0.0.1:7687 ESTABLISHED 1000 4908177 14182/firefox
tcp 0 0 10.0.1.11:38388 52.222.163.46:443 ESTABLISHED 1000 5190592 14182/firefox
tcp 0 0 127.0.0.1:39034 127.0.0.1:7687 ESTABLISHED 1000 4903190 14182/firefox
tcp 0 0 10.0.1.11:49408 216.58.209.238:443 ESTABLISHED 1000 4994841 14182/firefox
tcp 0 0 10.0.1.11:42724 172.217.18.197:443 ESTABLISHED 1000 5163155 14182/firefox
tcp 0 0 10.0.1.11:38316 52.222.163.46:443 ESTABLISHED 1000 5157419 7587/libpepflashpla
tcp 0 0 127.0.0.1:38632 127.0.0.1:7687 ESTABLISHED 1000 4853218 14182/firefox
tcp 0 0 10.0.1.11:39698 198.252.206.25:443 ESTABLISHED 1000 5159174 14182/firefox
tcp 0 0 10.0.1.11:58296 10.0.0.1:445 ESTABLISHED 0 4628873 -
tcp 0 0 127.0.0.1:39046 127.0.0.1:7687 ESTABLISHED 1000 4914563 14182/firefoxLike above, I will create a CSV :
FILE="$NEO4J_HOME/import/$1/network_connections.csv"I will split in two parts (with sub-parts), the import of this file :
-
processes that listen on a port
-
On IPv4
-
On IPv6
-
On all interfaces
-
-
processes that have an established connection
-
With an IPv4
-
With an IPv6
-
Processes that listen
On Ipv4
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/network_connections.csv" AS row
WITH
row,
toInteger(last(split(row.local, ':'))) AS local_port,
toInteger(split(row.pid,'/')[0]) AS pid
WHERE
row.state = 'LISTEN' AND
size(split(row.local, '.')) > 1 AND // only IPv4
(NOT row.local = '::' AND NOT row.local = '0.0.0.0') // Not for all interfaces
WITH
row,
replace(row.local, ':'+ local_port, '') AS local_ip,
local_port,
pid,
CASE WHEN pid IS NULL THEN [] ELSE [1] END AS ifPid
MATCH (i:Interface { ip: local_ip, fqdn:$fqdn })
MERGE (p:Port { number: local_port, ip:local_ip })
MERGE (i)-[:USES_PORT]->(p)
SET p.ip = i.ip,
p.ipv6 = i.ipv6
FOREACH( x IN ifPid |
MERGE (process:Process {pid:pid, fqdn:$fqdn})
MERGE (process)-[:LISTEN_ON]->(p)
);On Ipv6
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/network_connections.csv" AS row
WITH
row,
toInteger(last(split(row.local, ':'))) AS local_port,
toInteger(split(row.pid,'/')[0]) AS pid
WHERE
row.state = 'LISTEN' AND
size(split(row.local, '.')) = 0 AND // only IPv6
(NOT row.local STARTS WITH '::' AND NOT row.local STARTS WITH '0.0.0.0') // Not for all interfaces
WITH
row,
replace(row.local, ':'+ local_port, '') AS local_ip,
local_port,
pid,
CASE WHEN pid IS NULL THEN [] ELSE [1] END AS ifPid
MATCH (i:Interface { ipv6: local_ip, fqdn:$fqdn })
MERGE (p:Port { number: local_port, ipv6:local_ip})
MERGE (i)-[:USES_PORT]->(p)
SET p.ip = i.ip,
p.ipv6 = i.ipv6
FOREACH( x IN ifPid |
MERGE (process:Process {pid:pid, fqdn:$fqdn})
MERGE (process)-[:LISTEN_ON]->(p)
);On all interfaces
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/network_connections.csv" AS row
WITH
row,
toInteger(last(split(row.local, ':'))) AS local_port,
toInteger(split(row.pid,'/')[0]) AS pid
WHERE
row.state = 'LISTEN' AND
( row.local STARTS WITH '0.0.0.0') // all interfaces
WITH
row,
local_port,
pid,
CASE WHEN pid IS NULL THEN [] ELSE [1] END AS ifPid
MATCH (i:Interface {fqdn:$fqdn })
MERGE (p:Port { number: local_port, ip:i.ip})
SET p.ipv6 = i.ipv6
MERGE (i)-[:USES_PORT]->(p)
FOREACH( x IN ifPid |
MERGE (process:Process {pid:pid, fqdn:$fqdn})
MERGE (process)-[:LISTEN_ON]->(p)
);LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/network_connections.csv" AS row
WITH
row,
toInteger(last(split(row.local, ':'))) AS local_port,
toInteger(split(row.pid,'/')[0]) AS pid
WHERE
row.state = 'LISTEN' AND
( row.local STARTS WITH ':::*') // all interfaces
WITH
row,
local_port,
pid,
CASE WHEN pid IS NULL THEN [] ELSE [1] END AS ifPid
MATCH (i:Interface {fqdn:$fqdn })
MERGE (p:Port { number: local_port, ipv6:i.ipv6})
SET p.ip = i.ip
MERGE (i)-[:USES_PORT]->(p)
FOREACH( x IN ifPid |
MERGE (process:Process {pid:pid, fqdn:$fqdn})
MERGE (process)-[:LISTEN_ON]->(p)
);Graph example
This is so cool, at the end we obtain the graph below just by running the following query :
MATCH path=(n:Server {fqdn:'pythagore.logisima'})-[:HAS_INTERFACE]->(i:Interface)-[:USES_PORT]->(:Port)<-[:LISTEN_ON]-(p:Process)
RETURN path
Processes with a connection
This time, I import all the connections (incoming/outgoing) that computers have.
On Ipv4
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/network_connections.csv" AS row
WITH
row,
toInteger(last(split(row.local, ':'))) AS local_port,
toInteger(last(split(row.remote, ':'))) AS remote_port,
toInteger(split(row.pid,'/')[0]) AS pid
WHERE
row.state = 'ESTABLISHED' AND
size(split(row.local, '.')) > 1 // only ipv4
WITH
row,
replace(row.local, ':'+ local_port, '') AS local_ip,
local_port,
replace(row.remote, ':'+ remote_port, '') AS remote_ip,
remote_port,
pid,
CASE WHEN pid IS NULL THEN [] ELSE [1] END AS ifPid
MATCH (s:Server {fqdn:$fqdn})
MATCH (iLocal:Interface {ip: local_ip, fqdn:$fqdn })
MERGE (iLocal)-[:USES_PORT]->(pLocal:Port { number: local_port})
SET pLocal.ip = iLocal.ip,
pLocal.ipv6 = iLocal.ipv6
MERGE (iLocal)-[:USES_PORT]->(pLocal)
MERGE (pRemote:Port { number: remote_port, ip:remote_ip })
MERGE (con:Connection { fqdn:$fqdn, pid:coalesce(pid,'-'), local:row.local, remote:row.remote})
MERGE (con)-[:SOURCE]->(pLocal)
MERGE (con)-[:TARGET]->(pRemote)
FOREACH( x IN ifPid |
MERGE (process:Process {pid:pid, fqdn:$fqdn})
MERGE (process)-[:HAS_CONNECTION]->(con)
);On Ipv6
LOAD CSV WITH HEADERS FROM "file:///" + $fqdn + "/network_connections.csv" AS row
WITH
row,
toInteger(last(split(row.local, ':'))) AS local_port,
toInteger(last(split(row.remote, ':'))) AS remote_port,
toInteger(split(row.pid,'/')[0]) AS pid
WHERE
row.state = 'ESTABLISHED' AND
size(split(row.local, '.')) = 0
WITH
row,
replace(row.local, ':'+ local_port, '') AS local_ip,
local_port,
replace(row.remote, ':'+ remote_port, '') AS remote_ip,
remote_port,
pid,
CASE WHEN pid IS NULL THEN [] ELSE [1] END AS ifPid
MATCH (s:Server {fqdn:$fqdn})
MATCH (iLocal:Interface {ipv6: local_ip, fqdn:$fqdn })
MERGE (iLocal)-[:USES_PORT]->(pLocal:Port { number: local_port})
SET pLocal.ip = iLocal.ip,
pLocal.ipv6 = iLocal.ipv6
MERGE (pRemote:Port { number: remote_port, ip:remote_ip })
MERGE (con:Connection { fqdn:$fqdn, pid:coalesce(pid,'-'), local:row.local, remote:row.remote})
MERGE (con)-[:SOURCE]->(pLocal)
MERGE (con)-[:TARGET]->(pRemote)
FOREACH( x IN ifPid |
MERGE (process:Process {pid:pid, fqdn:$fqdn})
MERGE (process)-[:HAS_CONNECTION]->(con)
);Graph example
And the result is :
MATCH path=(n:Server {fqdn:'pythagore.logisima'})-[:HAS_INTERFACE]->(i:Interface)-[:USES_PORT]->(:Port)<-[:SOURCE]-(:Connection)-[:TARGET]->(p:Port)
OPTIONAL MATCH path2=(p)<-[:USES_PORT]-(:Interface)<-[:HAS_INTERFACE]-(:Server)
RETURN path, path2
Conclusion
It’s really cool to see all the components of a computer as a graph,
and if we do that on every computer of a network (hey nmap), we can have a complete vision of it, just with a discovery process.
In a next article, I will show you what we can do with those data, stay tune !