

Kettle
Kettle (or Pentaho Data Integration) is a well known ETL tool. It is mature tool, simple to learn due to its GUI and open-source.
Moreover, Kettle has a lot of plugins for all various data editors, so can really do every thing you want with your data. In this post, I will show you how to use the Neo4j components, but firstly, you need to have ketlle on your computer.
To install kettle, it’s pretty easy, you only need a JDK installed on your laptop (>= version 8), and then follow those steps :
-
Download the last binaries at this location : https://sourceforge.net/projects/pentaho/files/Data%20Integration/7.1/
-
Extract it
-
Run
spoon.sh
|
Note
|
Spoon is the application name of the graphic interface on which you will design your process |
Neo4j connector
There are some Neo4j connectors on the Kettle marketplace, but I strongly recommend you to use this one : https://github.com/knowbi/knowbi-pentaho-pdi-neo4j-output It is efficient, updated and maintained.
It is based on the official Neo4j Java Driver and have all the options you want to import your data in Neo4j, even on a cluster environment.
For now, this plugin is not on the marketplace but it will be.
How to install it
-
Go to this page https://github.com/knowbi/knowbi-pentaho-pdi-neo4j-output/releases/, and get the latest release.
-
Unzip it into the
pluginsfolder of your Kettle installation -
Restart spoon
Components
This plugin comes with 2+1 components :
-
Neo4j Cypher : a very useful component where you can write a cypher query, and it can be used as an input or output.
-
Neo4j Output : allow you to dynamically create (or update) nodes or relationships. It will generate the cypher query for you.
-
Neo4j Graph Output: By doing a graph mapping on the input fields, it will create/update the graph for you. But this component is in WIP.
Neo4j Cypher
This is (from my POV) the main component of this plugin (I’m a Cypher expert, so I like to write my own query ^^).
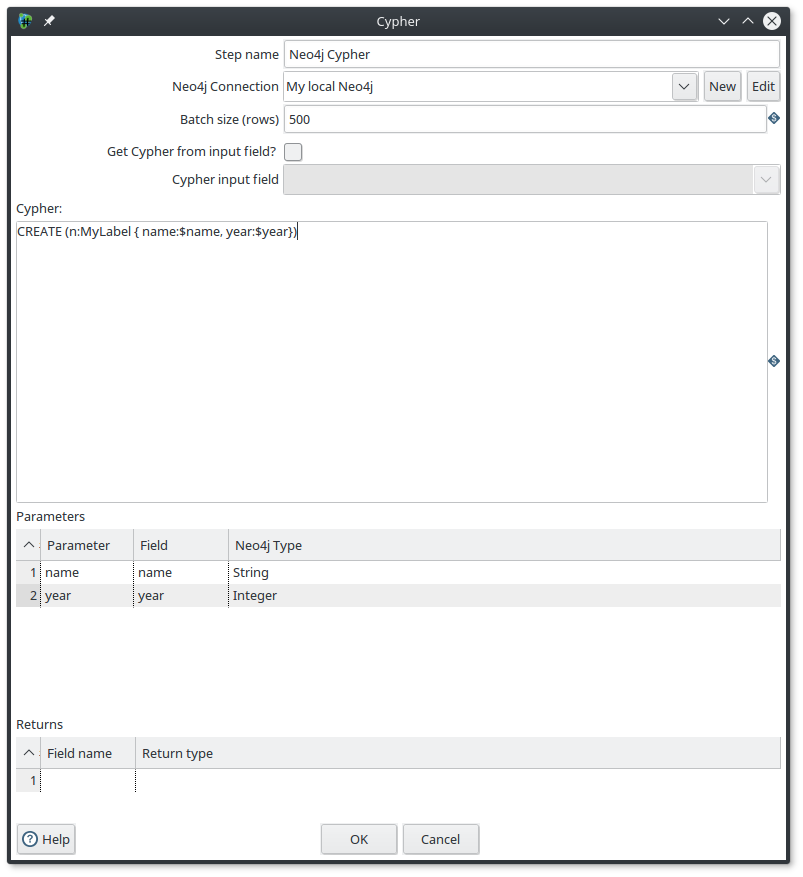
The first thing you need to do is to declare a Neo4j connection. If you have previously declare a Neo4j connection you can reuse it, otherwise you need to create a new one by fulfill this form :
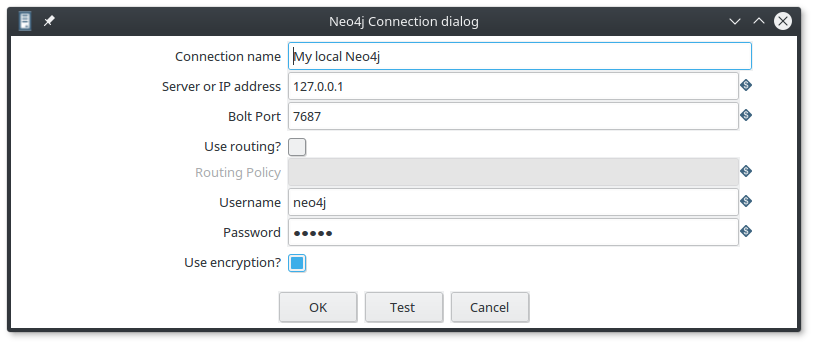
As you can see, the connection is using the Bolt protocol, and you can also configure a cluster connection with a routing policy. So it’s really complete.
The batch size parameter allow you define the size of your transaction.
In my example, Every 500 rows the component will do a commit.
This is really important to control the transaction size during an import process, to have the best performances.
Your Cypher query can be totally dynamic, ie, can be defined from an input field. To do it, you just have to enable the Get Cypher from input field? and then specify the Cypher input field.
Otherwise, you have to write your query in the Cypher field.
Another good point is that the component allows you to use query parameters.
In my example, $name and $year come from the input fields.
As you can see, I have defined them into the Parameters section, just below.
And last point, If you want to use this component as an Input one, you have to define the Returns section with the name and type.
For me, you have the hand on everything to create an efficient import process. The only lacks are in the UI (because I’m a lazy person ^^), where I would like to have :
-
a Get Fields button on the
Parameterssection, to fulfill it with all the input fields -
a compute return values button to automatically fulfill the
Returnsection.
The github issue is already created, and Matt Caster (the father of Kettle and one of the dev. of this plugin) is on it.
Neo4j Output
This component allow you to create nodes and relationships without writing a cypher query, it will do it for you.
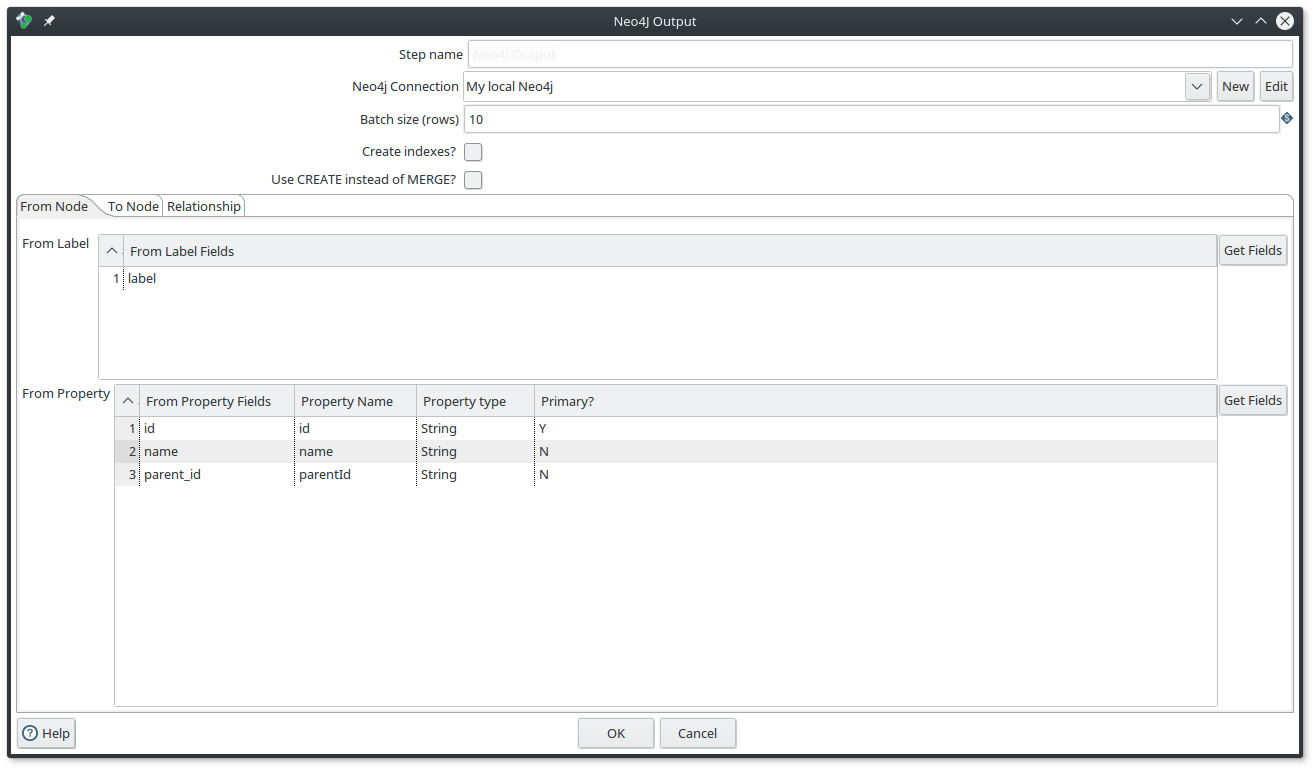
You can use it if you have Input fields define :
-
A node : you have to use only the
From Nodetab -
Two nodes plus the relationship between them : you have to define the
From node,To nodeandRelationshiptabulation.
Same as before, you can define the Batch size, and moreover you can also tell the component to create the Neo4j UNIQUE CONSTRAINTS for you if you enable the Create indexes? and specify the Primary fields.
This component has been designed to have the best performances for Neo4j. For example if you create nodes with a batch size, the component will collect your input fields in an array and generate a query like that :
WITH $data
UNWIND $data as $object
CREATE ....So you will not have many queries, but only one that match your batch size. This is really cool for performances.
Example for nodes and relationship
Imagine that you have the following input fields : label, id, name, parent_id, type
What you want to do is to create :
-
a node with the label
labeland with the propertiesidandname. -
a relationship between the current node and its
parent_idwith the typetype
Then you need to fulfill the component by following those screenshots
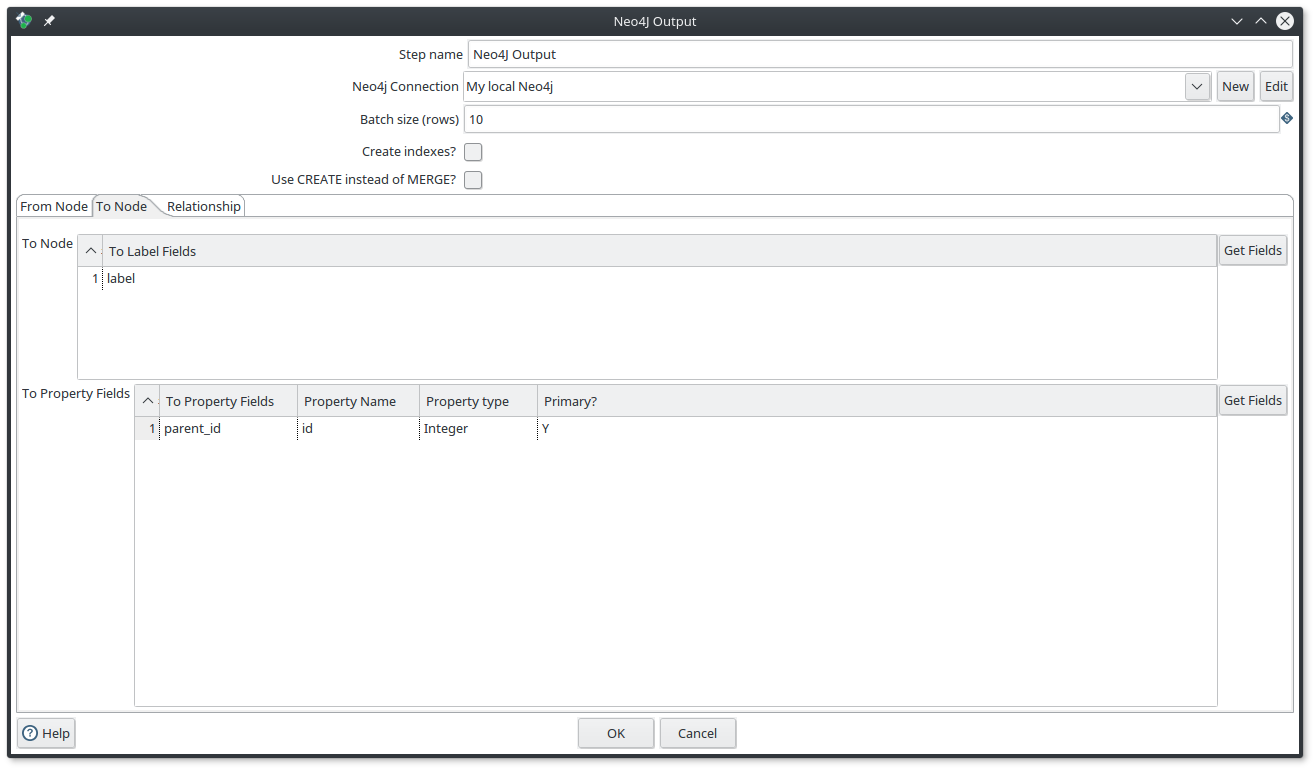
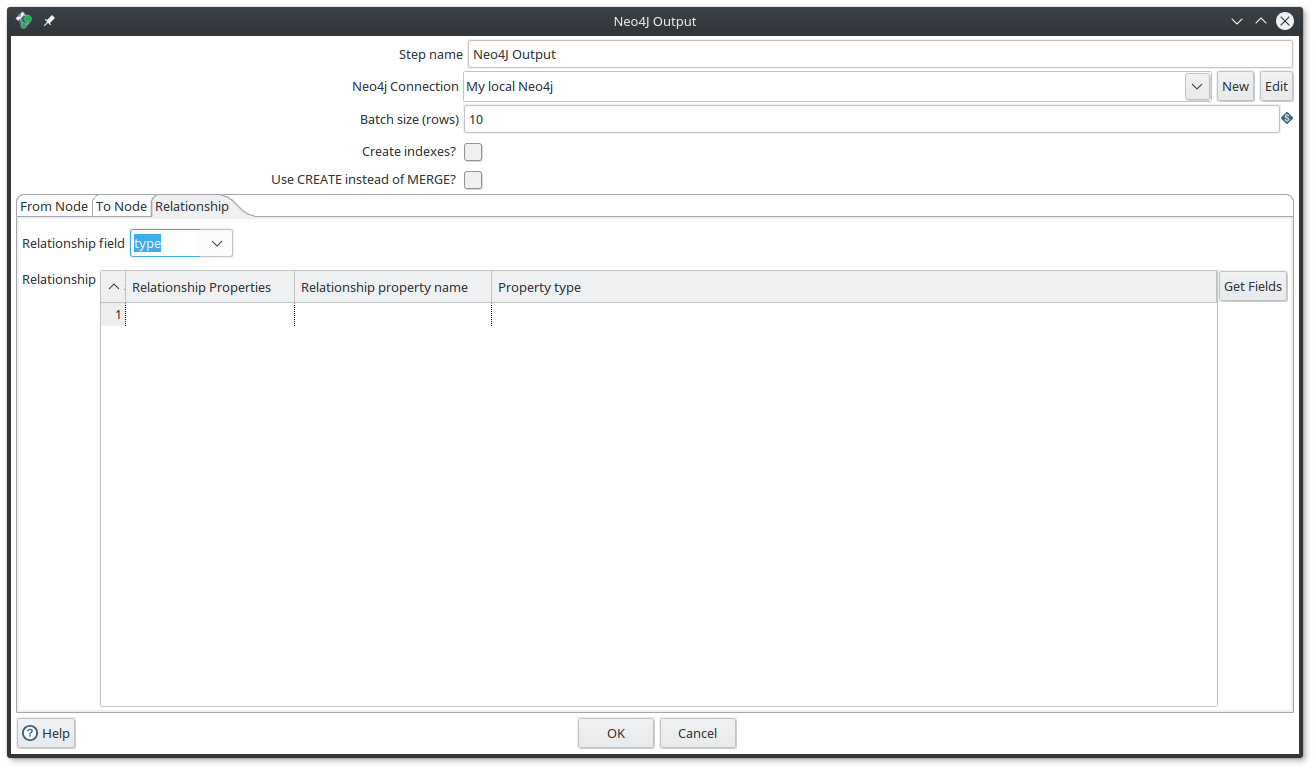
|
Note
|
don’t use the CREATE mode for such a process, otherwise the To node will be created each time.
|
Tips
This component needs to have an input field for the label of nodes and for the relationship type.
If you don’t have one because those value are static, you can use the Add constants component that allows you to a constant field to the fields :
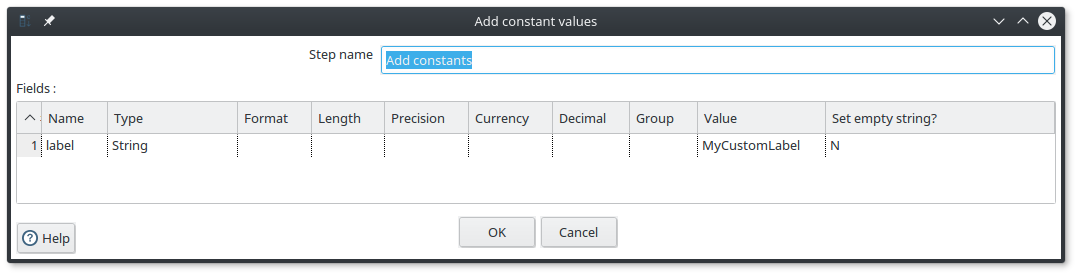
If you are using the MERGE mode, sometimes it is useful to define a default value for the property on which do the merge.
To do it, you can use the Value Mapper component like this :
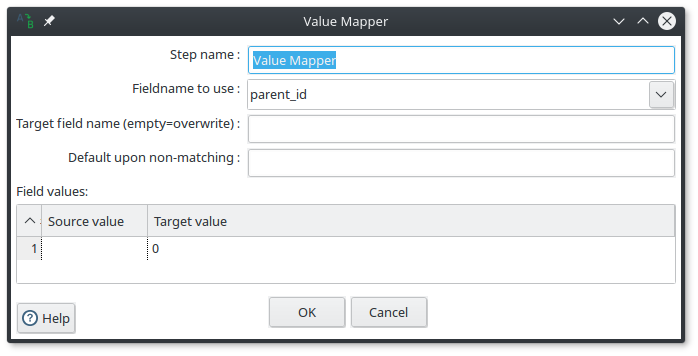
in this example, if the parent_id is not set, I replace it with the value 0.
Conclusion
This post is just an overview of Kettle, but as you can see its integration with Neo4j is really easy. I recommend you to test it, and if you have questions, requests or issues, don’t hesitate to create an issue on the github repository.
Have fun, and boil your graph imports !