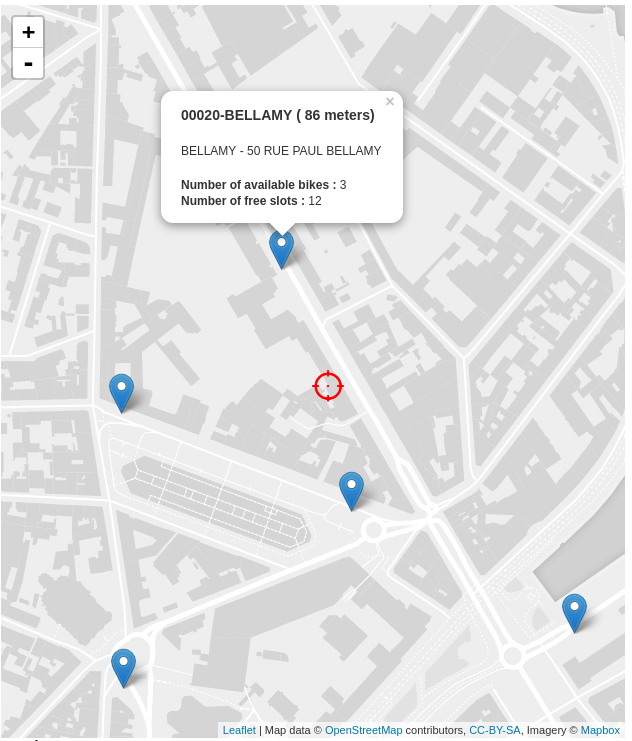
Goals
During this post, we will use Neo4j and JCDecaux opendata API, to find the % nearest stations from my position, with a free bike. I will show you how to design your graph, to load the dataset from the JSON API, and make some queries. As a bonus I have also build a simple javascript application to display the result.
Let’s start !
JCDecaux model
JCDecaux provide an API to get all the information about their bicycle services. All is documentated here : https://developer.jcdecaux.com
INFO: you need to create an API key to use the API. On my examples you should replace the @JCD_TOKEN_API@ by your own.
By reading the real-time API documentation, we can compute that JCD is using the following schema :
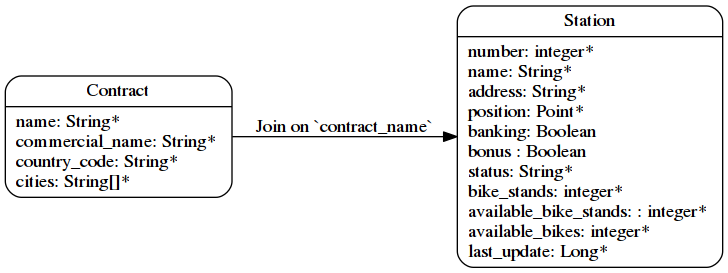
So we have two entities, related together : it’s a graph ! But can we do a better graph modelisation ?
If you look at the Contract entity, you can see :
-
a dependency to a country
-
a list of cities
So let’s explode this entity like this :

And what can we do about the Station entity ? It’s easy we can split it into two parts :
-
The station (static data)
-
The state of the station (ie. ephemeral data)
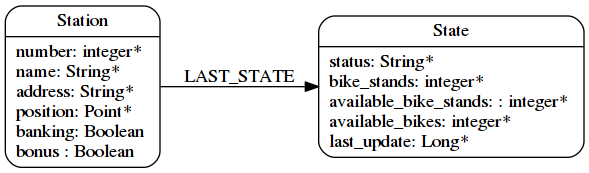
And what if I want to keep the state history ?
So let’s create a chain of State nodes.
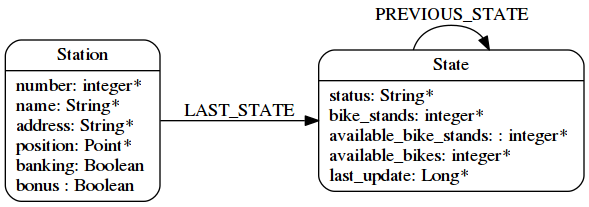
I have chosen this modeling, because my main goal is to get the last updated state, and with this one, I just have to traverse one relationship.
So the final schema looks like that :
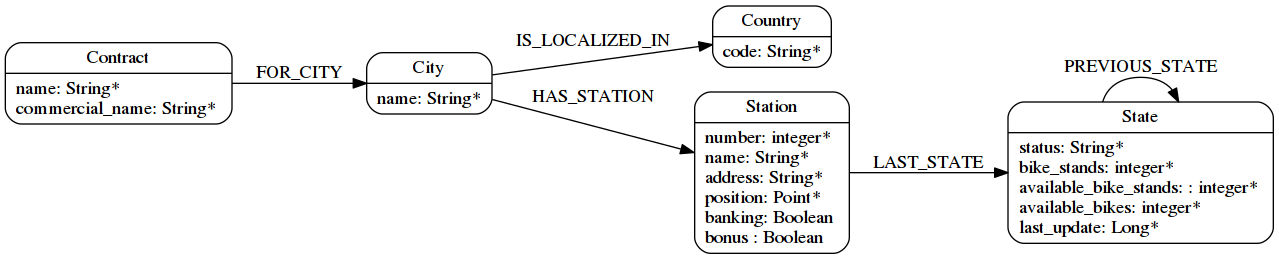
Now that we have our model, let see how to load the data.
Imports
APOC
Before to start, you need to install APOC. APOC is a collection of very usefull procedure for Neo4j.
This how to install it :
-
Download the jar here : https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/download
-
Put it into the neo4j
plugindirectory -
Restart your server
Constraints
Now we have to declare some constraints on our model, with all the unique keys :
// Contract name is unique
CREATE CONSTRAINT ON (n:Contract) ASSERT n.name IS UNIQUE;
// Country code is unique
CREATE CONSTRAINT ON (n:Country) ASSERT n.code IS UNIQUE;
// Station ID is a composition of the contract's name and the station id.
// Because the number field into the Station entity is only unique inside a contract
CREATE CONSTRAINT ON (n:Station) ASSERT n.id IS UNIQUE;
// State id is a composition of the station id plus the last_update timestamp
CREATE CONSTRAINT ON (n:State) ASSERT n.id IS UNIQUE;You can note here, that I haven’t create a constraint on cities. This is just because two countries can have a city with the same name. But we can create an index on it if we want to speed up our queries that are based on this field
CREATE INDEX ON :City(name);Importing all contracts
We will import all contracts of JCDecaux. To do this, there is an endpoint : https://api.jcdecaux.com/vls/v1/contracts
WITH '@JCD_TOKEN_API@' AS key
CALL apoc.load.json('https://api.jcdecaux.com/vls/v1/contracts?apiKey=' + key) YIELD value as row
MERGE (contract:Contract { name: row.name, commercial_name:row.commercial_name })
MERGE (country:Country { code: row.country_code })
WITH row, contract, country
UNWIND row.cities AS cityName
MERGE (country)-[:HAS_CITY]->(city:City { name: cityName })
MERGE (contract)-[:FOR_CITY]->(city)Importing station with their state
Now we are going to create stations with their data, for all contract, with the help of this endpoint : https://api.jcdecaux.com/vls/v1/stations?contract=@contract_name@
CALL apoc.periodic.iterate(
"MATCH (c:Contract) RETURN c",
"WITH '@JCD_TOKEN_API@' AS key , {c} AS contract
CALL apoc.load.json('https://api.jcdecaux.com/vls/v1/stations?contract=' + contract.name + '&apiKey=' + key) YIELD value as row
// we can find the same station number on two contracts, so the unique id is a compisition of the id and the contract
MERGE (contract)-[:HAS_STATION]->(station:Station {id: row.contract_name + '_' + row.number})
ON CREATE SET
station.number = row.number,
station.name = row.name,
station.address = row.address,
station.lat = row.position.lat,
station.lng = row.position.lng,
station.banking = row.banking,
station.bonus = row.bonus
// to have a unique id, I'm using a composition of the station id and the last_update timetsamp
MERGE (state:State {id: station.id + '_' + row.last_update})
ON CREATE SET
state.status = row.status,
state.available_bikes = row.available_bikes,
state.bike_stands = row.bike_stands,
state.available_bike_stands = row.available_bike_stands
WITH station, state
MERGE (station)-[:LAST_STATE]->(state)
// Here we remove the previous `LAST_STATE` rel if it exists, and we create the chain
WITH station, state
MATCH (old:State)<-[r:LAST_STATE]-(station)-[:LAST_STATE]->(state)
WHERE NOT id(old) =id(state)
WITH old, r, state
CREATE (state)-[:PREVIOUS]->(old)
DELETE r",
{batchSize:1,parallel:true}) YIELD batches, total, errorMessagesFirst instruction is apoc.periodic.iterate. It’s a APOC procedure that takes 3 parameters:
-
A cypher query that give a first collection of results
-
An other cypher query that will be applied on each result from the first one
-
Some configurations, here
{batchSize:1,parallel:true}
Basically, it’s the same as a WITH (ie. to iterate over the result of a query), with the ability to create some batches (based on the first query), and optionally to parallelize them.
So here, I’m just creating one job per Contract, to create all the corresponding Station with theirs State.
You can replay this script every 5 minutes, to update the state of each station.
To do this you can create a cron task, or you also can use the apoc.periodic.repeat procedure (Job are not persisted, so you will have to re-create it after each restart of neo4j).
At the end you should have a graph like this
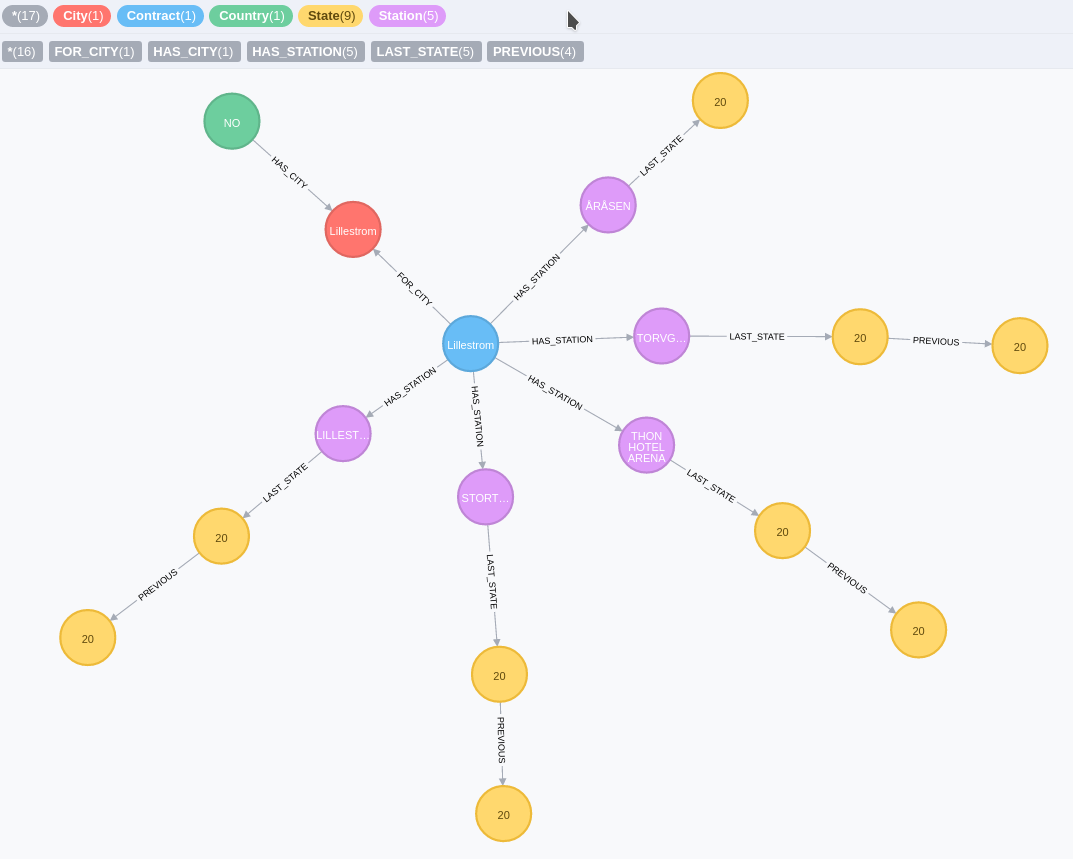
Some cool stuff
Now that we have the data, we can ask to the database, what is the nearest station from me with an available bike :
WITH point({latitude: 56.7, longitude: 12.6}) as my_position
MATCH (station:Station)-[:LAST_STATE]->(state:State)
WHERE state.status = "OPEN" AND state.available_bikes > 0
RETURN station, distance(point({latitude: station.lat, longitude: station.lng}), poi) AS distance
ORDER BY distance
LIMIT 5As you can see I’m using two new functions of Neo4j 3.1 :
-
point( { latitude: XXX, longitude: XXX} ) : allow you to create a geospatial point in WGS-83 projection
-
distance( point, point) : will returned the geodesic distance between the two points.
We can have a better performances, if we create those two indexes :
CREATE INDEX ON :State(available_bikes);
CREATE INDEX ON :State(status);To see the differences, just makes an explain before and after the creations of these indexes.
And what if we display this result directly on a map ? Nothing easier, Cypher can produce some JSON result, so let’s change the result to produce a geojson :
WITH point({latitude: 56.7, longitude: 12.6}) as my_position
MATCH (station:Station)-[:LAST_STATE]->(state:State)
WHERE state.status = "OPEN" AND state.available_bikes > 0
WITH station, state, distance(point({latitude: station.lat, longitude: station.lng}), my_position) AS distance
ORDER BY distance
LIMIT 5
WITH collect( {
type: 'Feature',
geometry: {
type: 'Point',
coordinates: [station.lng, station.lat]
},
properties : {
name : station.name,
distance: round(distance),
address : station.address,
free_bike: state.available_bikes,
free_slot: state.available_bike_stands
}
}) AS features
RETURN { type: 'FeatureCollection', features: features } AS geojsonTo see the result, you can copy/paste the json result on http://geojson.io/
Or you can also build a simple webpage to display the result with Leaflet, like this one.